Database Design – Assignment 3
Attributes of a Relational Databases [P1]
Definitions
Normalisation
When importing data into database software from files in various formats, such as a list of comma-separated values, normalisation is generally performed on the data. In most cases data in simple storage formats will be saved as a flat file. The data will not be divided into multiple tables, and will include a large amount of redundant data.
Entities
In reference to database design, entities are objects which data can be recorded about. The word is also used to refer to the tables and queries of a database that hold data about a given entity. Within a table fields can typically be found, which each hold data about the object; these are attributes of an entity.
Entities can be mapped using an entity relationship, or ER, diagram. These usually show all of or a handful of the entities within a database, and importantly show the naming used and the joins, or relationships, between different entities and attributes. An example ER diagram is shown below.
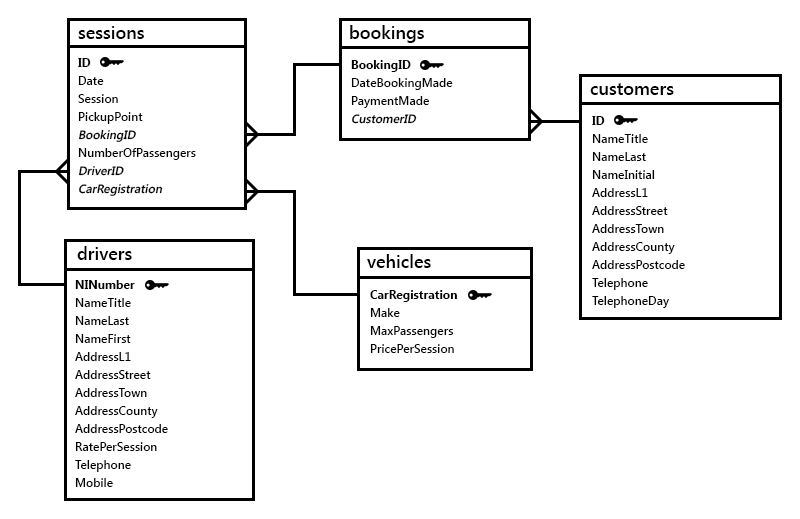 An entity relationship diagram shows the entities and attributes within a database.
An entity relationship diagram shows the entities and attributes within a database.
Attributes
A relational database stores information as records, or rows, in tables. These tables are comprised of a number of columns. A column is typically referred to as a field or attribute, and is accompanied by properties which detail its format and use. For example, a table to hold the names, email addresses and unique IDs of registered members of a website could contain four fields; id, email, name_last and name_first. These entities would need to each be assigned a type in order to be used to store data. Suggested MySQL data-types to use can be found in the table below.
| Field/Entity | Data-Type | Details |
|---|---|---|
id |
UNSIGNED INT |
An unsigned four-byte integer could be used, holding a value as high as 4,294,967,295, or 4.3 billion. Although a three-byte UNSIGNED MEDIUMINT could also be used, this would only be capable of holding 16.8 million users, a user count which many social networks exceed. The hassle of migrating data from one type to another would make the improved efficiency of a two- or three-byte type irrelevant. |
email |
VARCHAR(64) |
A string as long as 254 characters is used for the address, which would accommodate the longest valid email address. |
name_last |
VARCHAR(64) |
See above. The field would also be large enough to contain all but a very small number of potential names. |
name_first |
VARCHAR(64) |
See above. |
Once such a table has been populated, it may resemble the following:
id |
email |
name_last |
name_first |
|---|---|---|---|
| 0 | hello@jsmith.io | John | Smith |
| 2 | sayhi@gjon.es | Genny | Jones |
| 3 | wolfgang@wschmidt.de | Wolfgang | Schmidt |
| ... | ... | ... | ... |
The Relational Database Model
In a relational database tables are linked in such a way as to avoid the duplication of data and storing of redundant data. Some fields in some tables are filled with the unique primary keys of other records in order tables, allowing the data in the second to be retrieved as though is was part of the first. In addition to this most common one-to-many record system other configurations exist, such as one-to-one and many-to-many relationships. These may be found in more complex database designs.
To explain the use of relationships and relational tables, one could use the previous user table example. If at a later date, the administrators of such a database wished to add a further amount of fields to the table, the advantage of a relational database could be apparent. In some cases, duplicate data may exist in a table. For instance, if fields were added to the example table listing which area of the website's forum users most often visited, inefficiencies may be introduced. The name, number of members and web address of the forum area may all be included in separate fields in the users table, but this would lead to duplication. For any given value of area name, the user count and address could be predicted as they would always be the same. For this reason, only the name, or potentially the ID if available, of the area should be kept in the user table, and a link to another table containing further forum area information established. This means that changes made to the main forum area table would instantly propagate to any other uses of the data in other tables.
Keys and Referential Integrity [M1]
When managing a large database, it's a rarity that one will genuinely delete data. Tables and ranges of data within tables may be removed from a live database, but most often only if the data is backed up elsewhere or archived. In order to prevent the accidental removal of records, referential integrity is used. In order to maintain this, database storage engines such as InnoDB and that which is found in Microsoft Access use primary and foreign keys to understand the referencing of data between locations.
Primary Keys
In a database table one typically finds a number of fields, often represented as a columns of a table diagram. These fields, or entities, are filled with pieces of data, an entire set of which is referred to as a record. In order for specific records to be retrieved from the table, a primary key is usually set. The primary key field cannot contain any duplicated values throughout the table, and is used when querying the database to refer to single records. Most database software allows for the configuration of an auto-incrementing primary key field, which removes the need to manually set each new record's primary key. When a new record is created, the database software will increment the last record's primary key value, ensuring that this is unique and then using it to address the new record.
Although primary keys are not the only way to uniquely address single records, composite keys being another method, they are perhaps the simplest to understand and the most commonly used.
Foreign Keys
In a relational database, data is stored in a host of different tables in order to improve redundancy. There is no need to store the same values multiple times in a single table, and when multiple fields correlate they can be split into another. In order to link the split-away data to the original table, an entity relationship is created. The primary keys in the new table are used to refer to records in it, and the same keys appear in the original table. A key found in one table that links to the primary key in another table is referred to as a foreign key.
The relationships between tables and the use of primary and foreign keys are used by database software, when enforcing referential integrity, to determine if a record can be deleted or not.
Referential Integrity
In large production databases accidental deletion of records could have drastic effects, and the corruption of other areas of the database would be a particularly severe side effect. In order to prevent the removal of certains records of data, especially when other data in other database structures make reference to it, referential integrity can be enabled. If enabled, a record cannot be deleted if it has been linked to in another table by another field, which prevents the inadvertent creation of records which reference deleted data.
When enforcing referential integrity, the database will analyse the relationships between different tables and their primary and foreign keys. The deletion of records may be configured to cascade down from one record to many records, but more likely any record deletion that causes conflict will be prevented entirely. In terms of keys, a record containing a foreign key or whose primary key does not feature as a a foreign key in any other tables can normally be deleted without issue. In contrast, a record whose primary key is referenced in other records in other tables as a foreign key cannot normally be removed. If the removal was allowed, either the removal would need to cascade down to the foreign records referencing the record in question, or the foreign records would be left making reference to non-existent data.